Twitter Sentiment Analysis using Convolutional Neural Network CNN
- 15 minsintroduction
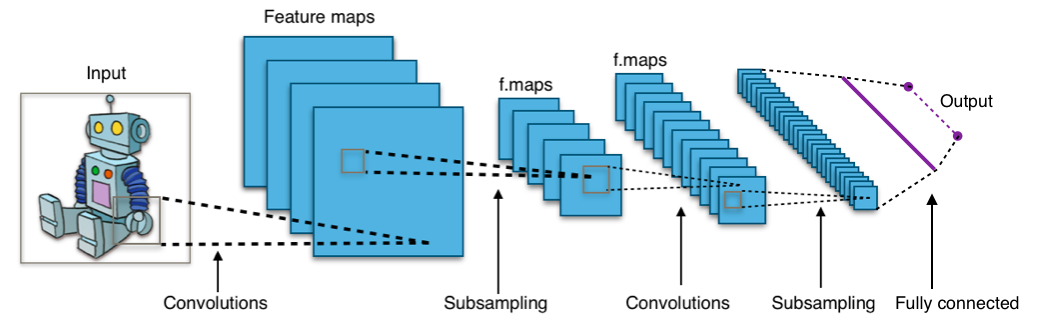
In machine learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks that has successfully been applied to analyzing visual imagery.
Convolutional neural newtorks is basically a multilayer perceptrons designed to require minimal preprocessing.CNN can also be called shift invariant or space invariant artificial neural networks (SIANN)because of their shared-weights architecture and translation invariance characteristics.
Convolutional networks were inspired by biological processes in that the connectivity pattern between neurons resembles the organization of the animal visual cortex. Individual cortical neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. The receptive fields of different neurons partially overlap such that they cover the entire visual field.
convolutional neural network ( CNN ) architectures make the explicit assumption that the inputs are images, which allows us to encode certain properties into the architecture. These make the forward function more efficient to implement and reduce the amount of parameters in the network.
Objective
we will implement multiclass sentiment or opinion mining using convolutional neural network by using KERAS link
Dataset
we downloaded the dataset from crowdflower
Decsription of the dataset
this dataset contains labels for the emotional content (such as happiness, sadness, and anger) of texts. Hundreds to thousands of examples across 13 labels.The dataset contains 40,000 rows
we import pandas and load the dataset
import pandas as pd
data = pd.read_csv('text_emotion.csv')
check the first five vrows of the dataset
data.head()
| tweet_id | sentiment | author | content | |
|---|---|---|---|---|
| 0 | 1956967341 | empty | xoshayzers | @tiffanylue i know i was listenin to bad habi... |
| 1 | 1956967666 | sadness | wannamama | Layin n bed with a headache ughhhh...waitin o... |
| 2 | 1956967696 | sadness | coolfunky | Funeral ceremony...gloomy friday... |
| 3 | 1956967789 | enthusiasm | czareaquino | wants to hang out with friends SOON! |
| 4 | 1956968416 | neutral | xkilljoyx | @dannycastillo We want to trade with someone w... |
check the number of class it contains
data.sentiment.value_counts()
neutral 8638
worry 8459
happiness 5209
sadness 5165
love 3842
surprise 2187
fun 1776
relief 1526
hate 1323
empty 827
enthusiasm 759
boredom 179
anger 110
Name: sentiment, dtype: int64
it contains 13 class But we will just extract all tweets that belong to only 3 classes (happiness, sadness and neutral )
data2 = data[(data.sentiment == 'happiness') | (data.sentiment == 'sadness') |(data.sentiment == 'neutral')]
data2.head()
| tweet_id | sentiment | author | content | |
|---|---|---|---|---|
| 1 | 1956967666 | sadness | wannamama | Layin n bed with a headache ughhhh...waitin o... |
| 2 | 1956967696 | sadness | coolfunky | Funeral ceremony...gloomy friday... |
| 4 | 1956968416 | neutral | xkilljoyx | @dannycastillo We want to trade with someone w... |
| 6 | 1956968487 | sadness | ShansBee | I should be sleep, but im not! thinking about ... |
| 8 | 1956969035 | sadness | nic0lepaula | @charviray Charlene my love. I miss you |
we check if the dataset is balanaced
data2.sentiment.value_counts()
neutral 8638
happiness 5209
sadness 5165
Name: sentiment, dtype: int64
The dataset is not balanaced because some class have more representatives than the other
we check the overall rows we have in our dataset
len(data2)
19012
we extract the features of interest to us (label and the tweets/text)
texts = data2.content
tags = data2.sentiment
we import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalMaxPooling1D
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from sklearn.preprocessing import LabelEncoder
import time
from keras import metrics
print('import done')
import done
num_max = 1000
# preprocess
le = LabelEncoder()
tags = le.fit_transform(tags)
tok = Tokenizer(num_words=num_max)
tok.fit_on_texts(texts)
mat_texts = tok.texts_to_matrix(texts,mode='count')
mat_texts.shape
(19012, 1000)
Building the model
# try a simple model first
def getModel():
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(num_max,)))
model.add(Dropout(0.2))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(3, activation='sigmoid'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc',metrics.sparse_categorical_accuracy])
print('compile done')
return model
def fitModel(model,x,y):
model.fit(x,y,batch_size=32,epochs=10,verbose=1,validation_split=0.2)
m = getModel()
fitModel(m,mat_texts,tags)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_10 (Dense) (None, 512) 512512
_________________________________________________________________
dropout_7 (Dropout) (None, 512) 0
_________________________________________________________________
dense_11 (Dense) (None, 256) 131328
_________________________________________________________________
dropout_8 (Dropout) (None, 256) 0
_________________________________________________________________
dense_12 (Dense) (None, 3) 771
=================================================================
Total params: 644,611
Trainable params: 644,611
Non-trainable params: 0
_________________________________________________________________
compile done
Train on 15209 samples, validate on 3803 samples
Epoch 1/10
15209/15209 [==============================] - 67s 4ms/step - loss: 0.9336 - acc: 0.5606 - sparse_categorical_accuracy: 0.5606 - val_loss: 0.8230 - val_acc: 0.6392 - val_sparse_categorical_accuracy: 0.6392
Epoch 2/10
15209/15209 [==============================] - 95s 6ms/step - loss: 0.7597 - acc: 0.6636 - sparse_categorical_accuracy: 0.6636 - val_loss: 0.8280 - val_acc: 0.6434 - val_sparse_categorical_accuracy: 0.6434
Epoch 3/10
15209/15209 [==============================] - 77s 5ms/step - loss: 0.6104 - acc: 0.7372 - sparse_categorical_accuracy: 0.7372 - val_loss: 0.9351 - val_acc: 0.6277 - val_sparse_categorical_accuracy: 0.6277
Epoch 4/10
15209/15209 [==============================] - 101s 7ms/step - loss: 0.4099 - acc: 0.8342 - sparse_categorical_accuracy: 0.8342 - val_loss: 1.2085 - val_acc: 0.6053 - val_sparse_categorical_accuracy: 0.6053
Epoch 5/10
15209/15209 [==============================] - 81s 5ms/step - loss: 0.2480 - acc: 0.9017 - sparse_categorical_accuracy: 0.9017 - val_loss: 1.4589 - val_acc: 0.6124 - val_sparse_categorical_accuracy: 0.6124
Epoch 6/10
15209/15209 [==============================] - 99s 7ms/step - loss: 0.1805 - acc: 0.9339 - sparse_categorical_accuracy: 0.9339 - val_loss: 1.7023 - val_acc: 0.6008 - val_sparse_categorical_accuracy: 0.6008
Epoch 7/10
15209/15209 [==============================] - 91s 6ms/step - loss: 0.1372 - acc: 0.9490 - sparse_categorical_accuracy: 0.9490 - val_loss: 2.0252 - val_acc: 0.5935 - val_sparse_categorical_accuracy: 0.5935
Epoch 8/10
15209/15209 [==============================] - 91s 6ms/step - loss: 0.1187 - acc: 0.9563 - sparse_categorical_accuracy: 0.9563 - val_loss: 2.0916 - val_acc: 0.5801 - val_sparse_categorical_accuracy: 0.5801
Epoch 9/10
15209/15209 [==============================] - 101s 7ms/step - loss: 0.1057 - acc: 0.9610 - sparse_categorical_accuracy: 0.9610 - val_loss: 2.3620 - val_acc: 0.5785 - val_sparse_categorical_accuracy: 0.5785
Epoch 10/10
15209/15209 [==============================] - 89s 6ms/step - loss: 0.0978 - acc: 0.9632 - sparse_categorical_accuracy: 0.9632 - val_loss: 2.2438 - val_acc: 0.5911 - val_sparse_categorical_accuracy: 0.5911
Convolutional Neural Network
# for cnn preproces
max_len = 100
cnn_texts_seq = tok.texts_to_sequences(texts)
print(cnn_texts_seq[0])
cnn_texts_mat = sequence.pad_sequences(cnn_texts_seq,maxlen=max_len)
[267, 141, 21, 4, 554, 13, 47, 291]
def getCNNmodel():
model = Sequential()
# we start off with an efficient embedding layer which maps
# our vocab indices into embedding_dims dimensions
# 1000 is num_max
model.add(Embedding(1000,
20,
input_length=max_len))
model.add(Dropout(0.2))
model.add(Conv1D(64,
3,
padding='valid',
activation='relu',
strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(256))
model.add(Dropout(0.2))
model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc',metrics.sparse_categorical_accuracy])
return model
m = getCNNmodel()
fitModel(m,cnn_texts_mat,tags)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 20) 20000
_________________________________________________________________
dropout_13 (Dropout) (None, 100, 20) 0
_________________________________________________________________
conv1d_3 (Conv1D) (None, 98, 64) 3904
_________________________________________________________________
global_max_pooling1d_3 (Glob (None, 64) 0
_________________________________________________________________
dense_17 (Dense) (None, 256) 16640
_________________________________________________________________
dropout_14 (Dropout) (None, 256) 0
_________________________________________________________________
activation_5 (Activation) (None, 256) 0
_________________________________________________________________
dense_18 (Dense) (None, 3) 771
_________________________________________________________________
activation_6 (Activation) (None, 3) 0
=================================================================
Total params: 41,315
Trainable params: 41,315
Non-trainable params: 0
_________________________________________________________________
Train on 15209 samples, validate on 3803 samples
Epoch 1/10
15209/15209 [==============================] - 41s 3ms/step - loss: 0.9968 - acc: 0.5046 - sparse_categorical_accuracy: 0.5046 - val_loss: 1.0146 - val_acc: 0.4544 - val_sparse_categorical_accuracy: 0.4544
Epoch 2/10
15209/15209 [==============================] - 56s 4ms/step - loss: 0.8861 - acc: 0.5853 - sparse_categorical_accuracy: 0.5853 - val_loss: 0.8801 - val_acc: 0.6066 - val_sparse_categorical_accuracy: 0.6066
Epoch 3/10
15209/15209 [==============================] - 67s 4ms/step - loss: 0.8164 - acc: 0.6330 - sparse_categorical_accuracy: 0.6330 - val_loss: 0.8155 - val_acc: 0.6398 - val_sparse_categorical_accuracy: 0.6398
Epoch 4/10
15209/15209 [==============================] - 40s 3ms/step - loss: 0.7889 - acc: 0.6474 - sparse_categorical_accuracy: 0.6474 - val_loss: 0.7997 - val_acc: 0.6500 - val_sparse_categorical_accuracy: 0.6500
Epoch 5/10
15209/15209 [==============================] - 57s 4ms/step - loss: 0.7652 - acc: 0.6584 - sparse_categorical_accuracy: 0.6584 - val_loss: 0.8689 - val_acc: 0.6221 - val_sparse_categorical_accuracy: 0.6221 - loss: 0.7650 - acc: 0.6585 - sparse_categorical_accuracy: 0.65
Epoch 6/10
15209/15209 [==============================] - 44s 3ms/step - loss: 0.7459 - acc: 0.6731 - sparse_categorical_accuracy: 0.6731 - val_loss: 0.8560 - val_acc: 0.6129 - val_sparse_categorical_accuracy: 0.6129
Epoch 7/10
15209/15209 [==============================] - 38s 2ms/step - loss: 0.7295 - acc: 0.6750 - sparse_categorical_accuracy: 0.6750 - val_loss: 0.8643 - val_acc: 0.6143 - val_sparse_categorical_accuracy: 0.6143
Epoch 8/10
15209/15209 [==============================] - 41s 3ms/step - loss: 0.7070 - acc: 0.6933 - sparse_categorical_accuracy: 0.6933 - val_loss: 0.8247 - val_acc: 0.6356 - val_sparse_categorical_accuracy: 0.63566967 - sparse_categorical - ETA: 5s - loss: 0.7004 - acc: 0.6969 - spars - ETA: 3s - loss: 0.7037 - acc: 0.69 - ETA: 0s - loss: 0.7069 - acc: 0.6933 - sparse_categorical_accuracy: 0.6 - ETA: 0s - loss: 0.7070 - acc: 0.6932 - sparse_categorical_accuracy
Epoch 9/10
15209/15209 [==============================] - 51s 3ms/step - loss: 0.6873 - acc: 0.7010 - sparse_categorical_accuracy: 0.7010 - val_loss: 0.9007 - val_acc: 0.5969 - val_sparse_categorical_accuracy: 0.5969
Epoch 10/10
15209/15209 [==============================] - 40s 3ms/step - loss: 0.6712 - acc: 0.7074 - sparse_categorical_accuracy: 0.7074 - val_loss: 0.8946 - val_acc: 0.6103 - val_sparse_categorical_accuracy: 0.6103
Another approach to CNN
def getCNNmodelEmbed(): # added embed
model = Sequential()
# we start off with an efficient embedding layer which maps
# our vocab indices into embedding_dims dimensions
# 1000 is num_max
model.add(Embedding(1000,
50, #!!!!!!!!!!!!!!!!!!!!!!!
input_length=max_len))
model.add(Dropout(0.2))
model.add(Conv1D(64,
3,
padding='valid',
activation='relu',
strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(256))
model.add(Dropout(0.2))
model.add(Activation('relu'))
model.add(Dense(3))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc',metrics.sparse_categorical_accuracy])
return model
m = getCNNmodelEmbed()
fitModel(m,cnn_texts_mat,tags)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, 100, 50) 50000
_________________________________________________________________
dropout_15 (Dropout) (None, 100, 50) 0
_________________________________________________________________
conv1d_4 (Conv1D) (None, 98, 64) 9664
_________________________________________________________________
global_max_pooling1d_4 (Glob (None, 64) 0
_________________________________________________________________
dense_19 (Dense) (None, 256) 16640
_________________________________________________________________
dropout_16 (Dropout) (None, 256) 0
_________________________________________________________________
activation_7 (Activation) (None, 256) 0
_________________________________________________________________
dense_20 (Dense) (None, 3) 771
_________________________________________________________________
activation_8 (Activation) (None, 3) 0
=================================================================
Total params: 77,075
Trainable params: 77,075
Non-trainable params: 0
_________________________________________________________________
Train on 15209 samples, validate on 3803 samples
Epoch 1/10
15209/15209 [==============================] - 87s 6ms/step - loss: 0.9847 - acc: 0.5126 - sparse_categorical_accuracy: 0.5126 - val_loss: 0.9604 - val_acc: 0.4581 - val_sparse_categorical_accuracy: 0.4581
Epoch 2/10
15209/15209 [==============================] - 75s 5ms/step - loss: 0.8470 - acc: 0.6092 - sparse_categorical_accuracy: 0.6092 - val_loss: 0.8269 - val_acc: 0.6334 - val_sparse_categorical_accuracy: 0.6334
Epoch 3/10
15209/15209 [==============================] - 74s 5ms/step - loss: 0.7830 - acc: 0.6531 - sparse_categorical_accuracy: 0.6531 - val_loss: 0.8547 - val_acc: 0.6258 - val_sparse_categorical_accuracy: 0.6258
Epoch 4/10
15209/15209 [==============================] - 74s 5ms/step - loss: 0.7500 - acc: 0.6722 - sparse_categorical_accuracy: 0.6722 - val_loss: 0.8453 - val_acc: 0.6329 - val_sparse_categorical_accuracy: 0.6329
Epoch 5/10
15209/15209 [==============================] - 76s 5ms/step - loss: 0.7079 - acc: 0.6935 - sparse_categorical_accuracy: 0.6935 - val_loss: 0.8613 - val_acc: 0.6327 - val_sparse_categorical_accuracy: 0.6327
Epoch 6/10
15209/15209 [==============================] - 72s 5ms/step - loss: 0.6665 - acc: 0.7138 - sparse_categorical_accuracy: 0.7138 - val_loss: 0.8697 - val_acc: 0.6324 - val_sparse_categorical_accuracy: 0.6324
Epoch 7/10
15209/15209 [==============================] - 78s 5ms/step - loss: 0.6190 - acc: 0.7405 - sparse_categorical_accuracy: 0.7405 - val_loss: 0.9466 - val_acc: 0.6179 - val_sparse_categorical_accuracy: 0.6179
Epoch 8/10
15209/15209 [==============================] - 68s 4ms/step - loss: 0.5812 - acc: 0.7583 - sparse_categorical_accuracy: 0.7583 - val_loss: 0.9649 - val_acc: 0.5969 - val_sparse_categorical_accuracy: 0.5969loss: 0.5805 - acc: 0.7592 - sparse_categorical_accurac
Epoch 9/10
15209/15209 [==============================] - 82s 5ms/step - loss: 0.5441 - acc: 0.7734 - sparse_categorical_accuracy: 0.7734 - val_loss: 0.9652 - val_acc: 0.5985 - val_sparse_categorical_accuracy: 0.5985
Epoch 10/10
15209/15209 [==============================] - 67s 4ms/step - loss: 0.5091 - acc: 0.7892 - sparse_categorical_accuracy: 0.7892 - val_loss: 1.0013 - val_acc: 0.6019 - val_sparse_categorical_accuracy: 0.6019 loss: 0.5078 - acc: 0.7897 - sparse_categorical_ac - ETA: 1s - loss: 0.5085 - acc: 0.7893 - sparse_categorical_a
Summary
Convolutional Neural Network handle overffiting much more better than simple neural network as we can see from the accuracy and the val_accuracy. the val_accuracy is about the data that the model never sees during the training and therefore cannot just memorize so they are good for the generalization of the model

Mustapha Omotosho
constant learner,machine learning enthusiast,huge Barcelona fan